28 KiB
Dégradation quotidienne des LLM : mythe vs réalité
La performance d'un LLM déployé peut-elle changer d'un jour à l'autre alors même que les poids du modèle sont figés ? Une plongée en profondeur dans les causes avérées, les bugs d'infrastructure et les facteurs psychologiques.
| ← Retour à Claude Code Best Practice |  |
 |
 |
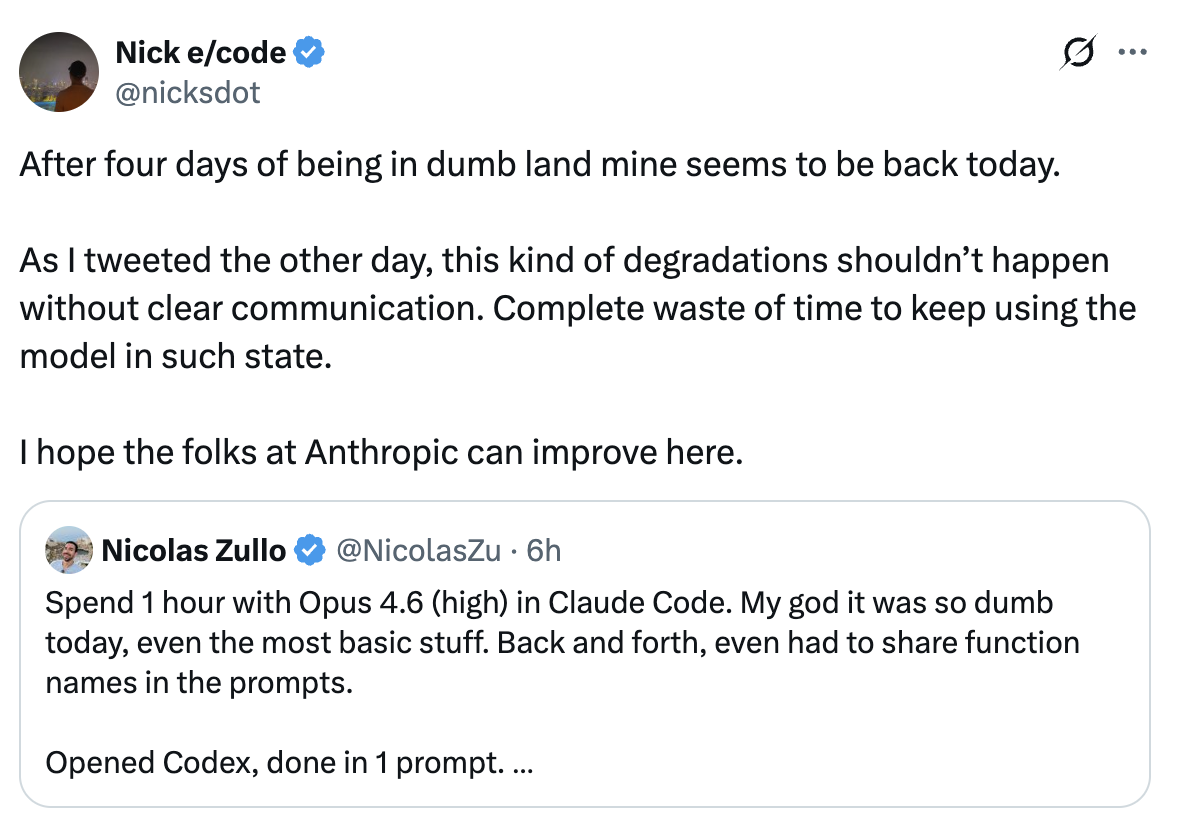
🔥 Analyse Claude Code Opus 4.6. High Reasoning
Quand Anthropic lance un modèle comme Opus 4.6, les poids du modèle — des milliards de paramètres appris — sont figés. L'entraînement est énormément coûteux (des millions de dollars, des semaines de calcul). Personne ne réentraîne le modèle du jour au lendemain.
Mais les poids ne sont qu'une couche d'un système bien plus large. La recherche révèle au moins 7 mécanismes distincts pouvant causer des changements de qualité réels ou perçus, même quand les poids du modèle sont figés.
| Question | Réponse |
|---|---|
| Les poids du modèle changent-ils après le lancement ? | Non — confirmé par tous les fournisseurs |
| Le modèle peut-il se comporter différemment au quotidien ? | Oui — prouvé avec une variance de ±8-14% |
| Est-ce un « nerfing » intentionnel ? | Non — aucune preuve de dégradation délibérée |
| Les bugs d'infrastructure sont-ils réels ? | Oui — Anthropic a confirmé 3 bugs affectant jusqu'à 16% des requêtes |
| Une partie est-elle psychologique ? | Oui — le biais de confirmation et les effets lune de miel sont réels |
| Les system prompts / le post-entraînement peuvent-ils changer ? | Oui — documenté chez les fournisseurs |
| Les utilisateurs devraient-ils se fier à leur perception ? | En partie — des causes réelles existent, mais la perception les amplifie |
La pile d'inférence complète
Les poids du modèle sont figés, mais neuf couches au-dessus d'eux peuvent indépendamment affecter ce que tu vis :
┌──────────────────────────────────────────────┐
│ CONTEXTE DE TA SESSION │ ← Se dégrade en session
│ (erreurs accumulées, longues conversations) │
├──────────────────────────────────────────────┤
│ SYSTEM PROMPT │ ← Mis à jour régulièrement
│ (règles de sécurité, instructions de compo.) │
├──────────────────────────────────────────────┤
│ POST-ENTRAÎNEMENT (RLHF / Fine-tuning) │ ← Peut être mis à jour discrètement
│ (suivi d'instructions, alignement sécurité) │
├──────────────────────────────────────────────┤
│ PARAMÈTRES D'ÉCHANTILLONNAGE │ ← Ajustables côté serveur
│ (temperature, top-p, top-k) │
├──────────────────────────────────────────────┤
│ DÉCODAGE SPÉCULATIF │ ← Qualité du draft model variable
│ (prédictions du draft model + vérification) │
├──────────────────────────────────────────────┤
│ ROUTAGE MoE / COMPOSITION DE BATCH │ ← variance ±8-14% prouvée
│ (quels experts s'activent par requête) │
├──────────────────────────────────────────────┤
│ ROUTAGE MATÉRIEL │ ← TPU vs GPU vs Trainium
│ (quel cluster sert ta requête) │
├──────────────────────────────────────────────┤
│ NIVEAU DE QUANTIFICATION │ ← Peut varier sous charge
│ (précision FP16 vs INT8 vs INT4) │
├──────────────────────────────────────────────┤
│ COMPILATEUR & RUNTIME │ ← bugs XLA prouvés réels
│ (XLA:TPU, CUDA, code spécifique au matériel) │
├──────────────────────────────────────────────┤
│ POIDS DU MODÈLE (FIGÉS) │ ← Ceux-ci NE changent PAS
│ (des milliards de paramètres appris) │
└──────────────────────────────────────────────┘
Le modèle mental clé : poids figés ≠ comportement figé. C'est comme dire « même moteur = même expérience de conduite » en ignorant les pneus, l'état de la route, la qualité du carburant et la fatigue du conducteur.
Causes avérées : bugs d'infrastructure
Le postmortem d'Anthropic de septembre 2025
En septembre 2025, Anthropic a publié un postmortem détaillé révélant trois bugs d'infrastructure distincts qui ont dégradé la qualité de Claude entre août et septembre 2025. Leur déclaration officielle :
« Nous ne réduisons jamais la qualité du modèle en raison de la demande, de l'heure de la journée ou de la charge serveur. Les problèmes rapportés par nos utilisateurs étaient dus uniquement à des bugs d'infrastructure. »
Bug nº1 — Erreur de routage de fenêtre de contexte
Des requêtes Sonnet 4 étaient accidentellement routées vers des serveurs configurés pour des fenêtres de contexte de 1M tokens au lieu de serveurs standard.
- Chronologie : Introduit le 5 août, aggravé le 29 août après un changement d'équilibrage de charge
- Impact maximal : 16% des requêtes Sonnet 4 affectées à la pire heure (31 août)
- Impact utilisateur : ~30% des utilisateurs de Claude Code ont eu au moins un message dégradé
- Détail insidieux : Le routage était « collant » — une fois sur un mauvais serveur, les requêtes suivantes y restaient
- Corrigé : 4–18 septembre (déployé sur les plateformes)
Bug nº2 — Corruption de sortie TPU
Une mauvaise configuration sur les serveurs TPU causait des erreurs durant la génération de tokens, assignant une forte probabilité à des tokens qui devraient rarement apparaître.
- Symptômes : Caractères thaï ou chinois apparaissant au milieu d'une réponse en anglais, erreurs évidentes de syntaxe de code
- Affectés : Opus 4.1 et Opus 4 (25–28 août), Sonnet 4 (25 août–2 septembre)
- Portée : API Claude uniquement ; plateformes tierces non affectées
- Corrigé : Rollback le 2 septembre
Bug nº3 — Mauvaise compilation XLA:TPU (le plus vicieux)
Un changement de code destiné à corriger des problèmes de précision a accidentellement exposé un bug de compilateur latent dans le XLA:TPU de Google.
- Cause racine : L'opération approximate top-k (utilisée pour choisir les tokens suivants les plus probables) « renvoyait parfois des résultats complètement faux, mais uniquement pour certaines tailles de batch et configurations de modèle »
- Pourquoi il était difficile à trouver : Il changeait de comportement selon les opérations exécutées avant ou après, et selon que les outils de débogage étaient activés ou non
- Caché pendant des mois : Un contournement précédent de décembre 2024 avait accidentellement masqué ce bug plus profond
- Affectés : Haiku 3.5 confirmé ; sous-ensemble de Sonnet 4 et Opus 3 suspectés
- Résolution : Passage de l'approximate top-k à l'exact top-k ; « impact mineur d'efficacité » accepté car « La qualité du modèle est non négociable »
Pourquoi la détection était difficile
Les évaluations automatisées d'Anthropic n'ont pas détecté la dégradation rapportée par les utilisateurs, « en partie parce que Claude se remet souvent bien des erreurs isolées ». Chaque bug produisait des symptômes différents sur différentes plateformes à des taux différents, créant « un mélange déroutant de rapports ne pointant vers aucune cause unique ».
Contexte clé : Claude tourne sur trois plateformes matérielles différentes (AWS Trainium, GPU NVIDIA, TPU Google), chacune avec des modes de défaillance, compilateurs et comportements de précision différents. Ta requête peut atterrir sur du matériel différent selon les jours.
Causes avérées : variance de routage MoE
Les grands modèles modernes utilisent souvent une architecture Mixture-of-Experts (MoE), où seul un sous-ensemble des paramètres du modèle (les « experts ») s'active pour chaque entrée. Un routeur appris décide quels experts utiliser.
La recherche de Scale AI a révélé un constat critique :
« La combinaison de MoE sparse et d'inférence par batch crée des résultats imprévisibles car la composition d'un batch peut déterminer vers quel expert ta requête est routée, et le mélange de requêtes d'autres utilisateurs dans le même batch n'est pas déterministe. »
Variance quotidienne mesurée chez les fournisseurs
| Fournisseur | Variance de score quotidienne |
|---|---|
| OpenAI (variantes GPT-4) | ±10–12% |
| Anthropic (variantes Claude) | ±8–11% |
| Google (variantes Gemini) | ±9–14% |
Exemple concret : le même modèle a obtenu 77% de résistance au jailbreak un jour et 63% le lendemain. Même modèle, mêmes poids, même test — 14 points de pourcentage d'écart dus à l'infrastructure seule.
Cela signifie que même avec zéro bug et zéro changement, le même modèle peut produire des sorties de qualité sensiblement différentes selon les jours, purement à cause de la façon dont les requêtes sont batchées et routées. Un test A/B ne peut détecter de façon fiable un signal de qualité de 5% quand le bruit quotidien est de 10–15%.
Causes avérées : mises à jour du system prompt & du post-entraînement
Changements de system prompt
Les poids du modèle ne changent pas, mais le system prompt qui enveloppe ces poids peut être mis à jour à tout moment. L'analyse de l'évolution du system prompt de Claude montre des dizaines d'itérations, avec des « hot-fixes » — courtes instructions ajoutées pour corriger un comportement indésirable — ajoutés et retirés régulièrement.
Le system prompt de Claude 3.7 contenait plusieurs instructions hot-fix ciblant des « pièges » courants des LLM. Le system prompt de Claude 4.0 les a tous retirés, les comportements étant traités pendant le post-entraînement via l'apprentissage par renforcement à la place.
La théorie du post-entraînement
La théorie la plus plausible pour les changements de qualité inexpliqués : les entreprises peuvent mettre à jour le fine-tuning et le RLHF (apprentissage par renforcement à partir de retours humains) sans changer les poids du modèle de base. Cela rendrait techniquement vrai de dire « le modèle n'a pas changé » tout en altérant le comportement via des garde-fous de sécurité mis à jour et des ajustements de suivi d'instructions.
Causes avérées : remplacements silencieux de modèle
OpenAI a été documenté à plusieurs reprises changeant silencieusement le modèle avec lequel les utilisateurs interagissent :
- Retrait du sélecteur de modèle du jour au lendemain, forçant les utilisateurs de GPT-4o vers GPT-5
- Transformation de GPT-4o en « modèle hérité » caché nécessitant un toggle manuel dans les réglages, sans notification in-app
- Un bug d'« autoswitcher » routant les utilisateurs vers de mauvais modèles
- En plus, des abonnés ont rapporté des modèles basculant vers une « version restreinte » sans consentement
Sam Altman a reconnu que le déploiement était « un peu plus cahoteux qu'espéré ». Des fils Reddit ont reçu des milliers d'upvotes qualifiant le nouveau modèle de « désastre » et de « régression ».
Cela démontre que les remplacements de modèle se produisent bel et bien dans l'industrie — parfois intentionnellement (décisions produit) et parfois accidentellement (bugs de routage).
Facteurs contributifs
Quantification sous charge
Pour servir des millions d'utilisateurs de façon rentable, les entreprises peuvent servir des versions quantifiées des modèles — réduisant la précision de FP16 à INT8 ou INT4. Cela peut réduire l'usage mémoire de 2–4× et accélérer l'inférence, mais introduit une perte de qualité subtile. Que les fournisseurs basculent dynamiquement les niveaux de quantification sous charge est débattu, mais la capacité technique existe et est bien documentée dans les frameworks de serving comme vLLM et TensorRT.
Décodage spéculatif
Les piles de serving modernes utilisent un plus petit modèle « draft » pour prédire plusieurs tokens à l'avance, puis font vérifier ceux-ci par le vrai modèle. Théoriquement cela préserve la même distribution de sortie, mais en pratique les taux d'acceptation varient selon le domaine et le contexte. Les draft models prêts à l'emploi peuvent bien fonctionner dans certains cas mais peinent souvent sur les tâches propres à un domaine ou les contextes très longs.
Pollution de la fenêtre de contexte
Dans une longue session de code, les erreurs antérieures s'accumulent dans le contexte. Le modèle voit ses propres erreurs et peut les perpétuer. C'est la cause la plus courante de « Claude est devenu plus bête » au sein d'une même session — ce n'est pas le modèle qui se dégrade, c'est la contamination du contexte.
Astuce pratique : Utilise /compact ou démarre de nouvelles sessions quand la qualité semble en baisse. C'est la chose la plus actionnable que tu puisses faire.
L'étude de Stanford — et pourquoi c'est compliqué
L'étude marquante de 2023 de Stanford et UC Berkeley (Chen, Zaharia, Zou) — « How is ChatGPT's Behavior Changing Over Time? » — est fréquemment citée comme preuve que les LLM se dégradent. Le constat phare :
La précision de GPT-4 sur « Ce nombre est-il premier ? Réfléchis étape par étape » est tombée de 97,6% à 2,4% entre mars et juin 2023.
Ce que l'étude a prouvé
- Le comportement du « même » service LLM peut changer substantiellement sur une courte période
- Différentes capacités peuvent évoluer en sens opposés (GPT-4 s'est dégradé en maths, GPT-3.5 s'est amélioré)
- La qualité de génération de code a chuté (code exécutable GPT-4 : 52% → 10%)
- L'étude a inventé le terme « LLM drift » (dérive des LLM)
Critiques méthodologiques
- La version de mars utilisait temperature 0,0 tandis que celle de juin utilisait temperature 1,0 — une variable confondante fondamentale qui augmente l'aléatoire
- Seulement 500 requêtes par tâche — trop peu pour des affirmations statistiques définitives
- Les « questions de maths » étaient en réalité des questions oui/non où le motif de devinette du modèle a changé, pas sa capacité mathématique
- Les changements reflétaient probablement des mises à jour de sécurité de post-entraînement intentionnelles, pas une dégradation
L'étude a prouvé quelque chose d'important — le comportement des LLM change avec le temps — mais le mécanisme était probablement des mises à jour intentionnelles, pas une dégradation involontaire.
La psychologie
Biais de confirmation
Une fois que quelqu'un tweete « Claude est bête aujourd'hui », tu commences à remarquer chaque erreur. Les jours où personne ne se plaint, tu balaies les mêmes erreurs. Les réseaux sociaux amplifient cet effet.
L'effet lune de miel
Les utilisateurs vivent une période de lune de miel initiale avec les nouveaux modèles, puis découvrent progressivement les limites. Le modèle n'a pas changé — les attentes se sont ajustées à la hausse plus vite que les capacités ne le justifiaient.
Variance de difficulté des tâches
Tes tâches varient d'un jour à l'autre. Une journée de problèmes difficiles donne l'impression que le modèle s'est dégradé, même quand ce n'est pas le cas.
Le mythe du « Claude du week-end »
Malgré la croyance de nombreux utilisateurs en des motifs selon le jour de la semaine, une analyse rigoureuse n'a trouvé aucune preuve cohérente de motifs de qualité selon le jour de la semaine. Une analyse intitulée « AI is Dumber on Mondays » n'a rien donné.
Nature stochastique des LLM
Les LLM sont probabilistes. Le même prompt peut produire des sorties différentes à chaque fois. Sur une série de malchance, tu pourrais obtenir plusieurs réponses médiocres d'affilée — pur hasard, pas dégradation.
Conclusion
Le phénomène que les utilisateurs décrivent est réel mais mal attribué :
- Correct : leur expérience s'est dégradée certains jours
- Incorrect : le modèle a été intentionnellement « nerfé »
Les causes réelles sont une combinaison de :
- Bugs d'infrastructure — prouvés par le postmortem d'Anthropic (jusqu'à 16% des requêtes affectées)
- Variance de routage MoE — écart de qualité de ±8-14% mesuré par Scale AI, même avec zéro changement
- Mises à jour du system prompt et du post-entraînement — documentées chez les fournisseurs
- Hétérogénéité matérielle — TPU vs GPU vs Trainium, chacun avec des modes de défaillance différents
- Pollution de contexte — les longues sessions dégradent la qualité en session
- Biais de confirmation — les réseaux sociaux amplifient les motifs perçus
- Variance stochastique — même modèle, même prompt, sortie différente à chaque fois
Le problème de mesure est sévère : une variance quotidienne de ±8-14% signifie que tu ne peux pas distinguer un changement de qualité réel de 5% du bruit. C'est pourquoi les camps « c'est dans ta tête » et « ils l'ont nerfé » se sentent tous deux confiants — le rapport signal/bruit rend impossible de trancher à partir d'une expérience individuelle seule.
Sources
- Anthropic: A Postmortem of Three Recent Issues — Postmortem officiel détaillant trois bugs d'infrastructure (septembre 2025)
- Anthropic Reveals Three Infrastructure Bugs — InfoQ — Analyse technique du postmortem
- How is ChatGPT's Behavior Changing Over Time? — Stanford/UC Berkeley — Étude marquante sur la dérive des LLM (2023)
- The Truth About ChatGPT's Degrading Capabilities — TechTalks — Critique méthodologique de l'étude de Stanford
- LLMs Are Getting Dumber and We Have No Idea Why — Ignorance.ai — Cinq théories sur la dégradation perçue
- When Claude Forgets How to Code — Robert Matsuoka — Analyse des fluctuations de qualité de Claude et causes d'infrastructure
- Smoothing Out LLM Variance — Scale AI — Variance quotidienne de ±8-14% mesurée chez les fournisseurs
- What We Can Learn from Anthropic's System Prompt Updates — PromptLayer — Analyse de l'évolution du system prompt
- Claude's System Prompt Changes Reveal Anthropic's Priorities — Drew Breunig — Motifs de hot-fix dans les system prompts
- Complaints About Secretly Switching Models — OpenAI Forum — Remplacements silencieux de modèle documentés
- Speculative Decoding — BentoML LLM Inference Handbook — Comment les draft models affectent le serving
- A Visual Guide to Mixture of Experts — Maarten Grootendorst — Architecture et routage MoE expliqués
🔥 Codex 5.3 High Reason and Finding
Périmètre du rapport
Cette section explique pourquoi les utilisateurs peuvent vivre une courte fenêtre où la qualité de sortie de Claude chute tandis que Codex 5.3 semble stable ou plus fort sur les tâches de code. L'accent n'est pas sur des classements permanents de qualité de modèle. L'accent est sur le comportement de production à court horizon dans des conditions de serving réelles.
Date du rapport : 5 mars 2026.
Motif observé
Le motif rapporté est :
- La qualité du modèle est acceptable pendant une période.
- La qualité semble se dégrader pendant plusieurs jours.
- La qualité revient près de la base précédente.
Cette forme est généralement un motif de pile de serving ou de déploiement, pas un changement permanent de capacité du modèle de base. Un déclin permanent de capacité ne récupérerait normalement pas aussi vite sans rollback ou correctif explicite.
High Reason : pourquoi Codex 5.3 peut paraître meilleur dans une mauvaise fenêtre
Codex 5.3 peut sembler nettement plus fort durant la période dégradée d'un autre fournisseur pour plusieurs raisons techniques pouvant toutes se produire en même temps :
- Adéquation à l'objectif produit. Codex 5.3 est optimisé pour la génération de code et les workflows de codage agentiques, donc même une force brute de modèle égale peut produire de meilleurs résultats de code grâce à l'orchestration d'outils, au raisonnement sur dépôt et au tuning d'instructions centré code.
- Différences de politique d'inférence. Les fournisseurs règlent la latence, la profondeur de raisonnement et les défauts de décodage indépendamment. Une politique plus conservatrice chez un fournisseur peut paraître « plus intelligente » qu'une politique agressive optimisée vitesse chez un autre le même jour.
- Séparation des chemins de serving. Même si deux fournisseurs hébergent des modèles de pointe, ils exécutent des couches de routage, des piles compilateur/runtime et des pipelines de déploiement différents. Un incident dans une pile n'implique pas une dégradation corrélée dans l'autre.
- Timing de déploiement et de rollback. Si un fournisseur est en plein déploiement tandis qu'un autre est stable, les utilisateurs peuvent voir une large divergence temporaire de qualité sans changement de fond à long terme des poids du modèle.
- Effets de contamination au niveau session. Dans de longues conversations de code, l'accumulation d'erreurs peut amplifier le déclin perçu. Un assistant concurrent peut sembler meilleur simplement parce que la session défaillante a été réinitialisée ou parce que sa boucle d'outils a récupéré plus vite.
Constat détaillé
Pour un rapport du type « Claude a paru très faible pendant environ quatre jours, puis est revenu », l'explication la plus probable est :
- Un incident côté fournisseur, un problème de routage, un bug de décodage/runtime ou une régression de déploiement a affecté un sous-ensemble des requêtes.
- Le problème a persisté assez longtemps pour être remarqué de façon répétée dans des workflows réels.
- Le problème a été corrigé ou annulé (rollback).
- La qualité perçue est revenue rapidement.
Durant cette même période, Codex 5.3 pouvait sembler substantiellement meilleur car il ne partageait pas le même chemin d'incident et parce que l'optimisation pour les tâches de code amplifiait l'écart de résultats pratiques.
Classement des hypothèses pour ce motif
| Hypothèse | Vraisemblance | Justification |
|---|---|---|
| Incident fournisseur plus rollback | Élevée | Meilleure correspondance pour un creux multi-jours suivi d'une récupération rapide |
| Changement de configuration de serving (échantillonnage/latence/budget de raisonnement) | Élevée | Source courante de changements brusques de comportement sans réentraînement du modèle |
| Mouvement silencieux d'alias ou de snapshot | Moyenne-Élevée | Peut changer le comportement sans action visible de l'utilisateur |
| Dérive de prompt et contamination de contexte uniquement | Moyenne | Peut dégrader les sessions, mais moins susceptible d'expliquer seul de larges rapports multi-jours |
| Dégradation permanente du modèle de base | Faible | Incohérente avec le retour rapide à la qualité précédente |
Ce qui confirmerait ou réfuterait ce constat
Pour transformer cela d'une inférence à haute confiance en preuve solide, collecte de la télémétrie au niveau requête pour le même jeu de tâches sur plusieurs jours :
- Identifiant exact du modèle et snapshot/alias au moment de la requête.
- Toute empreinte de backend ou marqueur de version exposé par le fournisseur.
- Paramètres de décodage (temperature, top_p, top_k, max tokens).
- Traces de latence, de timeout et de taux d'erreur.
- Scores de qualité structurés sur un jeu de prompts de benchmark de code fixe.
- Longueur de session et profondeur de contexte en tokens aux points de défaillance.
Si les baisses de qualité corrèlent avec une fenêtre d'incident, un changement de config ou un changement d'empreinte de backend, l'hypothèse incident/config est confirmée. Si aucun tel changement n'existe et que la dégradation n'est que dans les longues sessions, la contamination de contexte devient l'explication principale.
Conseils d'ingénierie pratiques
Pour réduire la variance quotidienne en production :
- Épingle les snapshots de modèle quand disponibles au lieu d'utiliser des alias flottants.
- Stocke les métadonnées de requête (ID de modèle, paramètres, latence, erreurs, label de qualité de réponse).
- Exécute une suite canary quotidienne fixe pour les tâches de code et alerte sur régression.
- Réinitialise ou compacte les sessions de longue haleine après plusieurs tours échoués.
- Garde un chemin de fournisseur/modèle de repli pour les fenêtres d'incident.
- Sépare « qualité du modèle » et « fiabilité de serving » dans les tableaux de bord internes.
Conclusion finale
Codex 5.3 paraissant meilleur durant une courte fenêtre de dégradation de Claude est un résultat techniquement plausible et attendu dans les opérations LLM modernes. L'explication la plus solide n'est pas un effondrement permanent du modèle. L'explication la plus solide est une dégradation temporaire du chemin de serving chez un fournisseur, combinée à une optimisation spécifique au code et à un fonctionnement stable chez l'autre fournisseur durant la même période.